
Deep|LLM: Frontier Compute for AGI in the U.S., Cost-Driven Adoption and Video Platforms in China
AI Is Splitting in Two

AI competition has evolved from a single race to a bifurcated landscape. In the U.S., labs invest heavily in large compute clusters, pursuing AGI through increased computational power and advanced systems engineering. In contrast, China focuses on cost optimization, large-scale deployments, and rapid integration of AI into consumer infrastructure.
Model selection is now a significant factor in financial planning. With high-frequency, multi-agent workloads consuming millions of tokens, the cost per token has become as important as model performance.
Control over the compute stack is now a key competitive advantage. At scale, system efficiency—including interconnects, power, scheduling, and integration—outweighs individual chip specifications. This will distinguish profitable leaders as the AI industry matures.
Seedance takes a distinct approach. China’s first credible contender for video AI leadership relies on extensive content data, strong platform distribution, and a focus on price-performance rather than sheer computational power.
AI video is increasingly functioning as consumer internet infrastructure rather than enterprise SaaS. As generation costs decrease, value shifts toward distribution, user engagement, and monetization, favoring those who control creator ecosystems and supporting infrastructure.
GPT-Codex-5.3: Rapid catch-up driven by a new compute generation and systems engineering
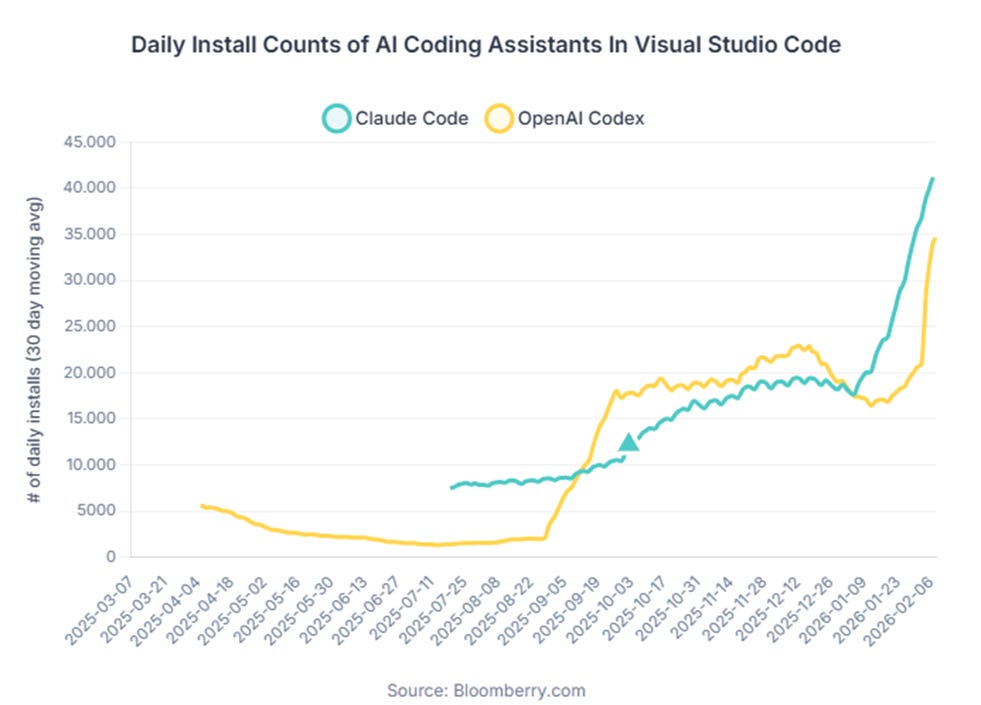
While 2025 was seen as a period of slower model progress, early 2026 has reversed this trend. The consecutive releases of Claude Opus 4.5 and 4.6, along with the rapid adoption of Claude Code, have made long-horizon collaboration a tangible product feature. This has increased both inference session length and compute consumption.
OpenAI responded with GPT-5.3-Codex, designed specifically for engineering workflows and agent applications. Public benchmarks indicate strong performance in coding and terminal-focused evaluations (SWE-Bench Pro, Terminal-Bench, OSWorld). The model is closely integrated with NVIDIA’s GB200 NVL72 stack for both training and deployment. Developer feedback suggests that Codex 5.3 and Claude 4.5/4.6 are both competitive in practical coding scenarios, each offering distinct strengths.
The full release of GPT-5.3 is expected to be a significant improvement over GPT-5.2. GPT-5.2 introduced a larger parameter base, while GPT-5.3 builds on this with additional training and optimization. Earlier experiments used the H-series GPU stack, but GPT-5.3-Codex was retrained primarily on GB200 NVL72 systems with a greater emphasis on coding and agent data. GPT-5.3-Codex likely uses tens of billions of active parameters, compared to the hundreds of billions in Claude Opus 4.5/4.6 and the larger Sonnet 4.5. This difference highlights OpenAI’s focus on efficiency optimization.
We’ve previously argued that Anthropic’s lead in coding partly stems from two structural choices. First, they moved early (1H24) into large-scale synthetic data generation for coding and agent workflows, effectively creating tool-use environments where models could explore and generate their own training traces. Second, their pretraining mix has relatively low multimodal exposure but an unusually high allocation to coding and agent data. In that sense, Claude can reasonably be viewed as a coding-specialist lineage.
In our view, Codex 5.3’s rapid progress highlights two broader industry dynamics:
Model advancement now appears to depend more on compute scale and systems optimization than on proprietary research breakthroughs.
As leading labs break down capability improvements into pre-training, mid-training, reinforcement learning, verifiable environments, and agent data feedback, methodological expertise spreads rapidly. The primary competitive barrier is now operational: the ability to deploy large-scale compute, maintain throughput, and reduce unit costs over time.
US hyperscalers’ financial performance: sustained competitiveness depends on converting compute investments into incremental profit.
One of the clearest takeaways from the latest MAG7 prints is how quickly Google Cloud has moved from “growth story” to “profit engine.” In Q1’24, Google Cloud posted $9.574B of revenue and ~$0.9B of operating income (roughly ~9% op margin).
By Q4 FY’25 (reported Feb 4, 2026), Cloud revenue scaled to ~$17.7B (+48% YoY) and operating income to ~$5.3B, implying ~30% operating margin.
This level of margin increase was uncommon in the traditional cloud era, where high capital expenditures and depreciation limited profitability. In an AI-focused cloud environment, GCP’s margin expansion reflects two key factors:
AI workloads result in significantly higher utilization. These jobs are longer-running and require greater throughput than traditional SaaS, maximizing capacity and maintaining high system activity.
Google’s vertical stack lowers the unit cost of compute. By optimizing TPU, networking, scheduling, and datacenter operations, Google can serve demand with a stronger gross margin profile.
Market sentiment is supporting Google’s focus on compute. Alphabet has projected capital expenditures of $175–185 billion in 2026, primarily for AI infrastructure. Management also noted a Cloud backlog of approximately $240 billion in contracted but unrecognized revenue, providing greater visibility into future capital needs.
From this perspective, the challenges for competitors, particularly Microsoft, are clear. Azure’s strength lies in distribution, including enterprise relationships and procurement. However, the key issue is the completeness of its technology stack: custom silicon development, network architecture, and integrated datacenter design. While Microsoft is developing in-house chips such as Maia and Cobalt, its vertical integration lags behind the most optimized stacks, and Azure remains reliant on NVIDIA GPUs for advanced AI workloads.
In summary, compute is a core competitive advantage in the AI industry. Providers that convert AI compute demand into incremental operating profit, rather than focusing solely on revenue growth, will remain competitive as the industry consolidates around a few large, integrated platforms.
A key principle in AI competition is that success depends on controlling the compute stack and maximizing efficiency, rather than simply increasing GPU count.
Many still equate AI compute with GPU count, but this metric becomes less relevant beyond approximately 10,000 GPUs. At this scale, system design—including interconnect bandwidth, network topology, scheduling, cooling, power infrastructure, and software optimization—becomes the primary determinant of performance. In some cases, the main constraint is energy and infrastructure, rather than the chips themselves.
Google currently leads in developing its own compute stack. The latest TPU generation, Ironwood, emphasizes datacenter-level optimization and aggressive cluster scaling using OCS optical switching. Clusters can scale to approximately 9,216 chips, with significant improvements in HBM capacity, bandwidth, and chip-to-chip interconnect. For example, at a 10,000-accelerator scale, a TPUv7 cluster may outperform a GB200-based cluster in total cost of ownership and sometimes in system efficiency, despite higher hardware costs for GB200. The primary factor is interconnect bandwidth: 400 Gb for GB200 deployments versus 4.8 Tb for TPUv7 architectures. At this scale, system efficiency is more important than individual chip specifications.
On the model side, Google is likely to keep releasing specialized models, including coding-focused systems competing with Codex 5.3 and Claude 4.5/4.6. More importantly, Google appears to have enough compute headroom to dedicate substantial capacity (potentially on the order of 30%) to higher-risk efforts, such as unified multimodal models (multi-modal in, multi-modal out). That kind of experimentation is expensive, and only players with abundant, vertically integrated compute can comfortably sustain it.
xAI has prioritized maximizing compute density before addressing cost efficiency. The Colossus datacenter exemplifies this approach by concentrating hundreds of thousands of GPUs in a single location, selecting sites for future expansion, and managing power supply, including large-scale gas generation. This strategy has delivered short-term gains, as increased compute density has led to rapid model capability improvements. However, competing on long-term cost against organizations with fully integrated compute stacks, such as Google, is more challenging. Simply acquiring more GPUs does not replicate the system efficiency or long-term total cost of ownership advantages of integrated solutions.
This perspective has led Musk to consider deeper integration within the compute stack. If energy is the primary constraint, altering the energy environment becomes a strategic lever. Should Starship reduce launch costs to approximately $200 per kilogram, orbital data centers could become viable. With stable, high-intensity solar energy in space, certain workloads—such as batch inference, data generation, and other latency-insensitive tasks—could operate at lower energy costs per token. While this may not suit low-latency, real-time applications, it could benefit large offline workloads. If feasible, the next step would be to design ASICs tailored for this environment to further reduce compute costs.
Anthropic, meanwhile, has already experienced the downside of constrained compute access. Around 2025, heavy reliance on a single cloud provider and a specific chip roadmap created friction in training cadence and resource allocation. Early work with AWS Trainium 2 involved ecosystem maturity issues, tooling stability challenges, and practical efficiency gaps that reportedly slowed progress. At the same time, AWS prioritized datacenter and energy resources toward Trainium deployments, tightening GPU availability. Even when switching back to NVIDIA made sense, flexibility was limited. Since then, Anthropic seems to have moved toward a more pragmatic multi-cloud strategy: continuing to use GPUs while also leaning more on TPU capacity, especially Google-style superpod clusters built around datacenter-scale optimization and optical switching, which provide more flexibility for large-scale training and cross-cluster scaling.
OpenAI, traditionally aligned with NVIDIA, is now adopting a multi-chip strategy. NVIDIA is also expanding partnerships across the accelerator ecosystem, including with AMD and Cerebras. Concurrently, OpenAI is collaborating with Broadcom to develop custom AI silicon, aiming for a TPU-style, vertically integrated ASIC stack. The industry trend is clear: long-term advantage depends on controlling the compute stack for cost, efficiency, and scalability, rather than merely acquiring more GPUs.
Kimi, Qwen, DeepSeek, GLM, MiniMax, Doubao: China’s agent-model push is still fundamentally about cost efficiency, and unlikely to materially dent the growth trajectory of top US labs
OpenClaw is pushing personal agents from “cool demo” to high-frequency billing, and model choice is quickly becoming a cost decision
OpenClaw’s recent surge in attention comes down to one shift: moving AI from something that mainly chats to something that can actually operate a computer and execute tasks. That reframes the whole personal-agent discussion. Developer interest picked up quickly, expectations around AI assistants became more concrete, and the founder’s recent move to OpenAI, with the project transitioning to a foundation-led open-source model, signals that personal agents are now viewed by frontier labs as a core product direction rather than an experiment.
OpenClaw introduces a new workflow structure that typically involves multiple agents operating in parallel, extended context windows, and frequent tool use. A single complex coding session can consume 1–3 million tokens, and running several sub-agents in parallel increases this further. As a result, users are increasingly selecting models based on cost rather than maximum intelligence.
OpenRouter usage data indicates that open-source and lower-cost models now lead the rankings. Models such as MiniMax, Kimi, DeepSeek, and GLM are consistently popular. The developer community has adopted a tiered routing approach, assigning complex tasks to frontier models like Opus and routine tasks to more affordable engines such as Kimi or DeepSeek. Cost control is becoming a primary factor in real-world model adoption.
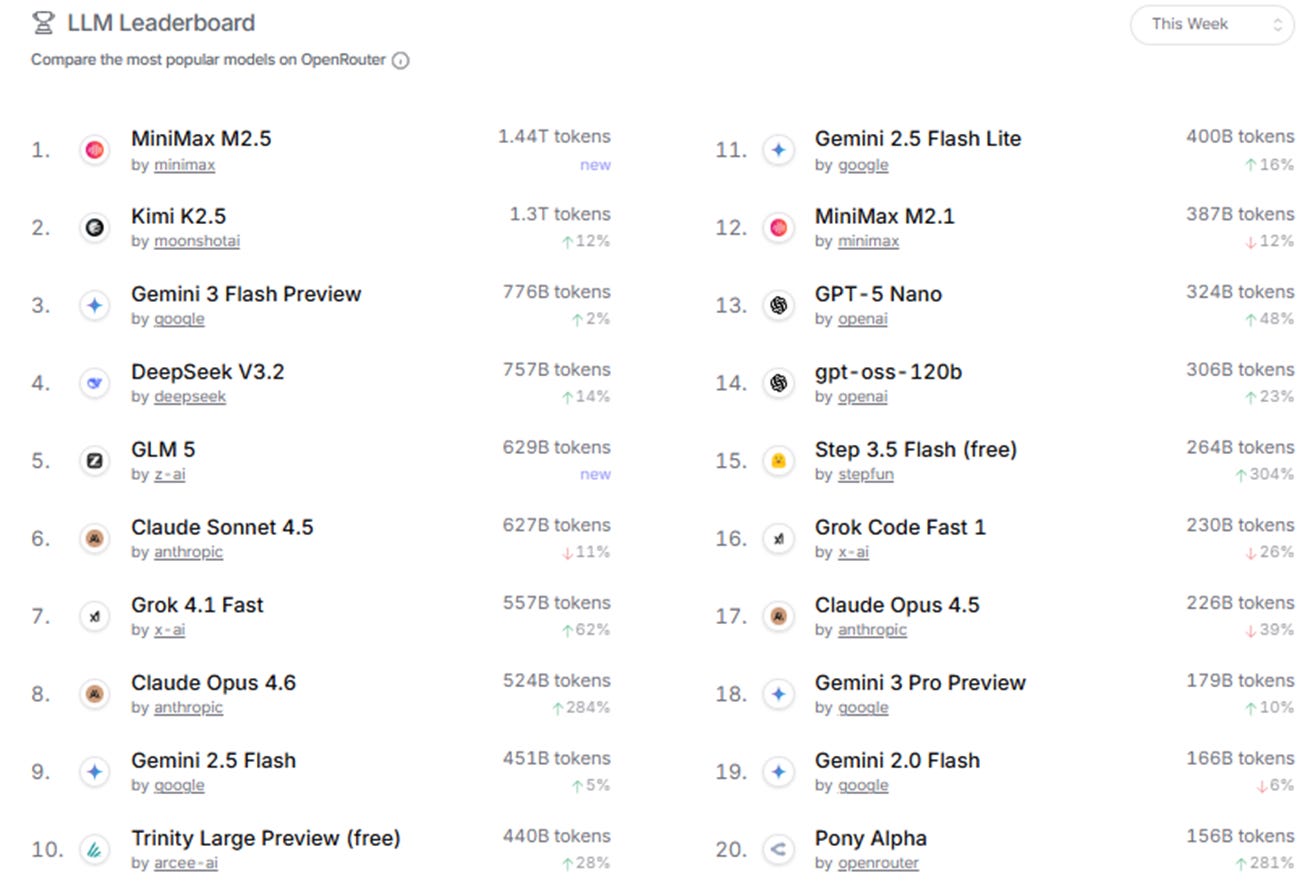
Chart: OpenRouter model usage statistics: MiniMax and Kimi rank #1 and #2; four of the top five models are from Chinese labs.
The recent increase in adoption is primarily due to improved agent capabilities and aggressive optimization of Mixture-of-Experts (MoE) active parameters and inference engineering.
On the supply side, there’s been a noticeable cluster of new releases from Chinese labs that quickly filled the execution-layer gap for agent workloads. The models are generally “good enough” for real tasks, but are priced far more aggressively. During OpenClaw’s peak buzz window (roughly Feb 11–14), several flagship launches landed almost back-to-back — GLM-5, MiniMax M2.5, and ByteDance’s Seed (Doubao) 2.0 series — effectively competing head-on for the agent-engine slot.
