Deep|3Q25 PreER Playbook



Before we head into the 3Q25 earnings season, we want to lay out our views on all AI-related stocks and provide an interim wrap-up. Everything here is grounded in our prior reports and recent field research, and you can easily find the supporting evidence in our past publications.
As we move into 3Q25 earnings, we’ll publish more preview updates, and our views may evolve accordingly.
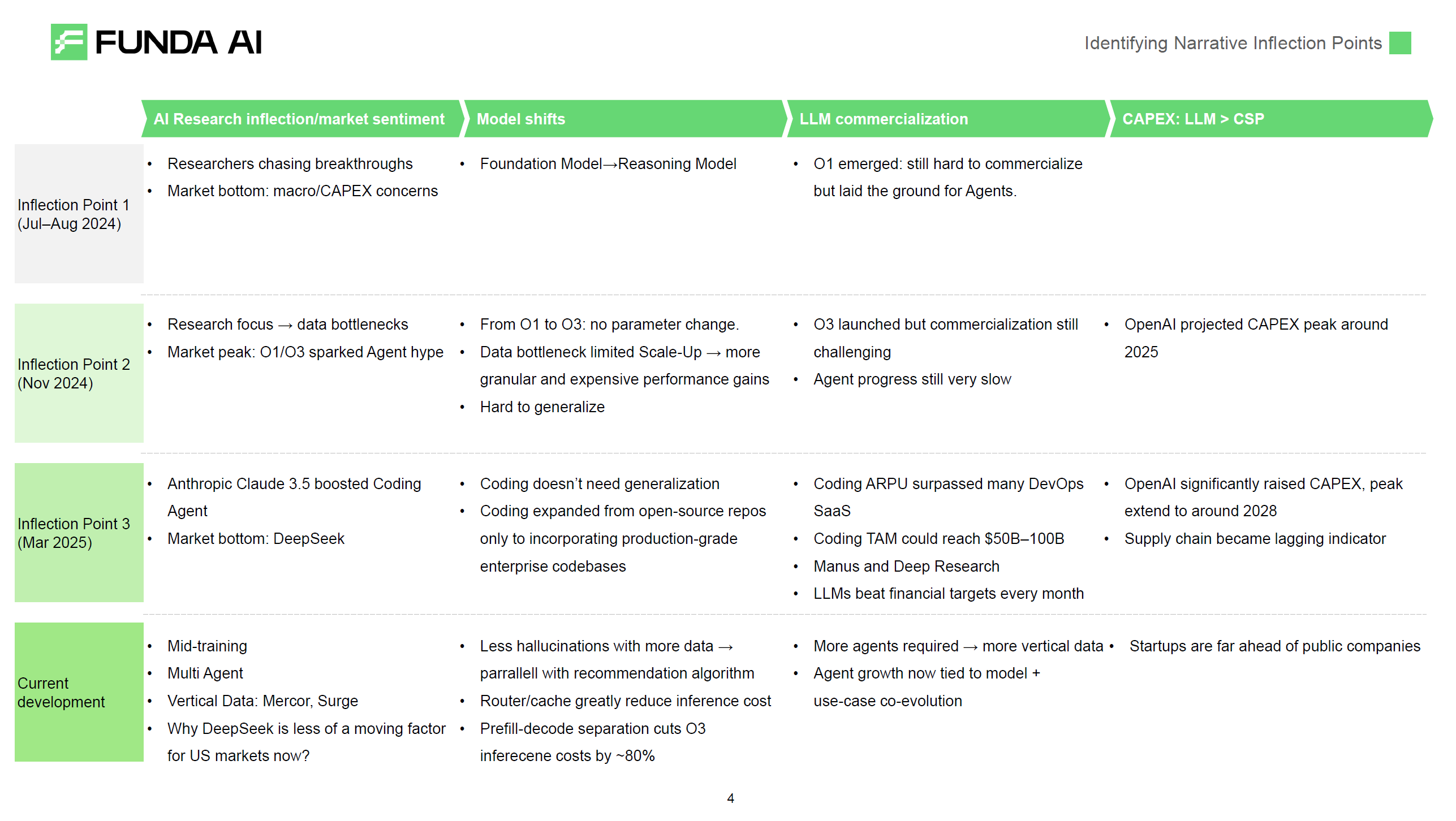
We’ve experienced three AI narrative shifts over the past year. FundaAI’s research team alerted at nearly every critical narrative shift timing.
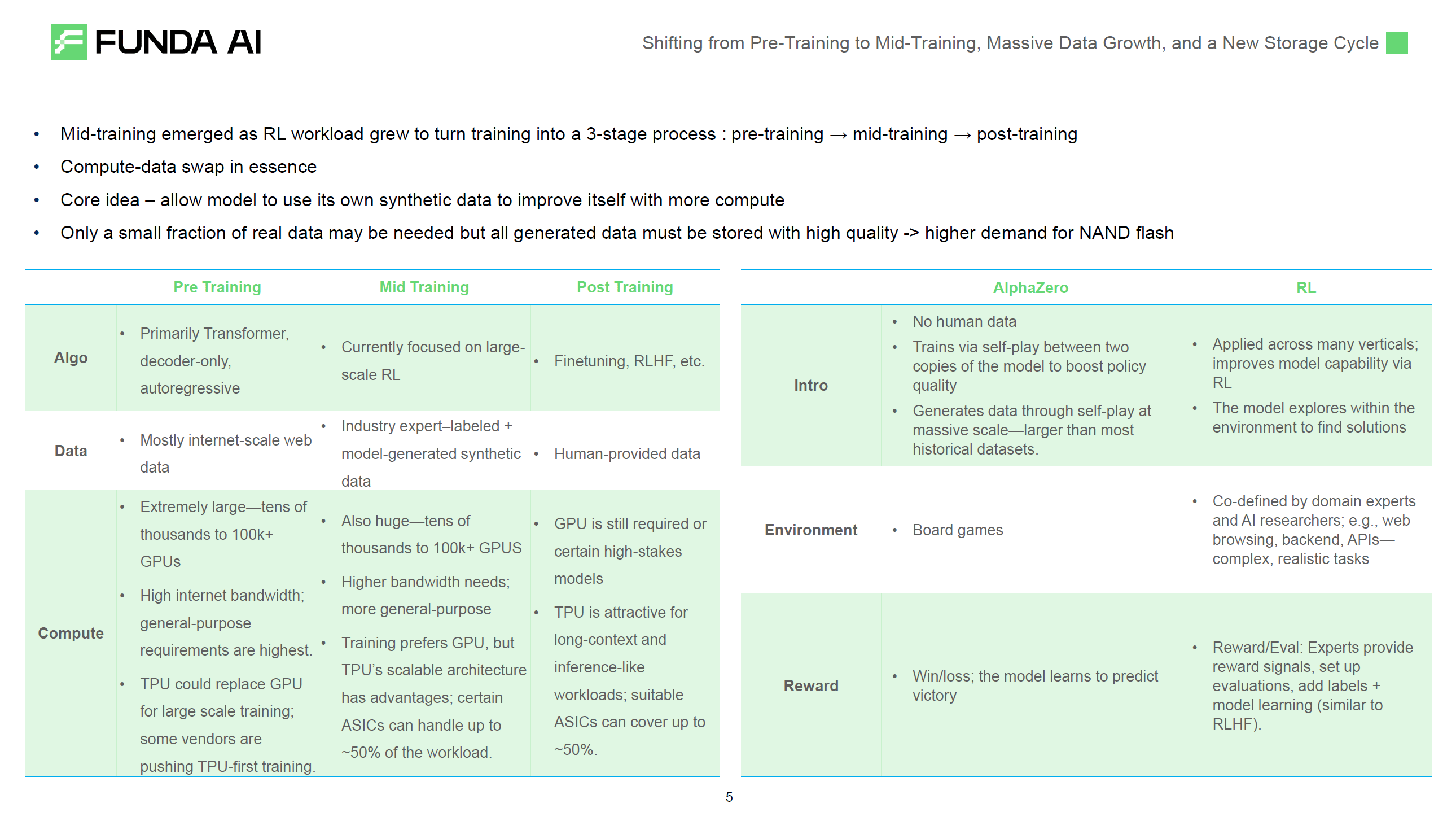
The first narrative shift occurred in July-August 2024. The market was at bottom, with significant concerns about CAPEX and macro risks. But researchers were excited about post-training, as top-2 LLMs’ post-training compute usage exceeded pre-training during this period. Strawberry had major weekly updates throughout these months. In our observation, frontline researchers’ sentiment changes typically lead the market by 2-3 months. The market quickly turned optimistic after the launch of O1 Reasoning Models.
The second narrative shift was in November-December 2024. The market was filled with optimism about O1 and O3, believing O3’s emergence meant vertical agents would explode. But we observed researchers’ sentiment actually turned negative during this period. Data bottlenecks arrived quickly, and top-3 LLMs hoped self-play would bring generalization capabilities, but extremely difficult. This was directly reflected in the models - O1 and O3 had the same parameter count, even though data got more detailed. Hundreds of researchers were responsible for synthetic data efforts in coding, math, physics But you’d see that number of PhDs became the clear bottleneck for data scale-up at this stage.
The third narrative shift happened in March this year. Coding Agent ARR grew rapidly from under $700M ARR in end of 2024 to $2.2B ARR by June 2025, and will likely reach $5B ARR by end of 2025. Coding Agents’ most typical characteristic is ARPU far exceeding prosumer SaaS products, and they don’t require generalization. When Anthropic introduced larger-scale codebases during mid-training, they found data bottleneck issues in coding were much smaller than other domains. This had a huge impact on the entire AI industry. LLM companies discovered the first market beyond ChatGPT that could reach significant TAM within 3 years, and this market has data flywheel effects. With this clear market, no one can lose the battle. Meanwhile, coding brought clear revenue acceleration for LLMs - since March, LLM companies have beat their original revenue plans almost every month, allowing them to budget more for moonshot-level innovations.
We’re still continuing the March 2025 trend. Comparatively, LLM companies talk more about mid-training, while agent companies discuss multi-agent and vertical data more. Mercor and Surge have become the engines of the AI agent industry. If you can find 100 super experts who can define opening questions in a vertical domain, you can scale up vertical data through mid-training, leading to vertical AGI. This is what we’ve been doing since our founding this year. To achieve this path, vertical data labeling provides the workflow for defining opening questions, multi-agent provides the information filtering method, and mid-training provides the scale-up path. I believe this latest narrative shift may last a long time, potentially continuing until the AGI endpoint.